Андрей Карпати 7 января опубликовал первую версию nanochat miniseries. Идея простая: хватит думать об обучении одной модели. Думайте о семействе моделей, которое управляется одним параметром — compute. Крутите ручку вверх, получаете предсказуемо лучший результат. Всё.
В чём суть
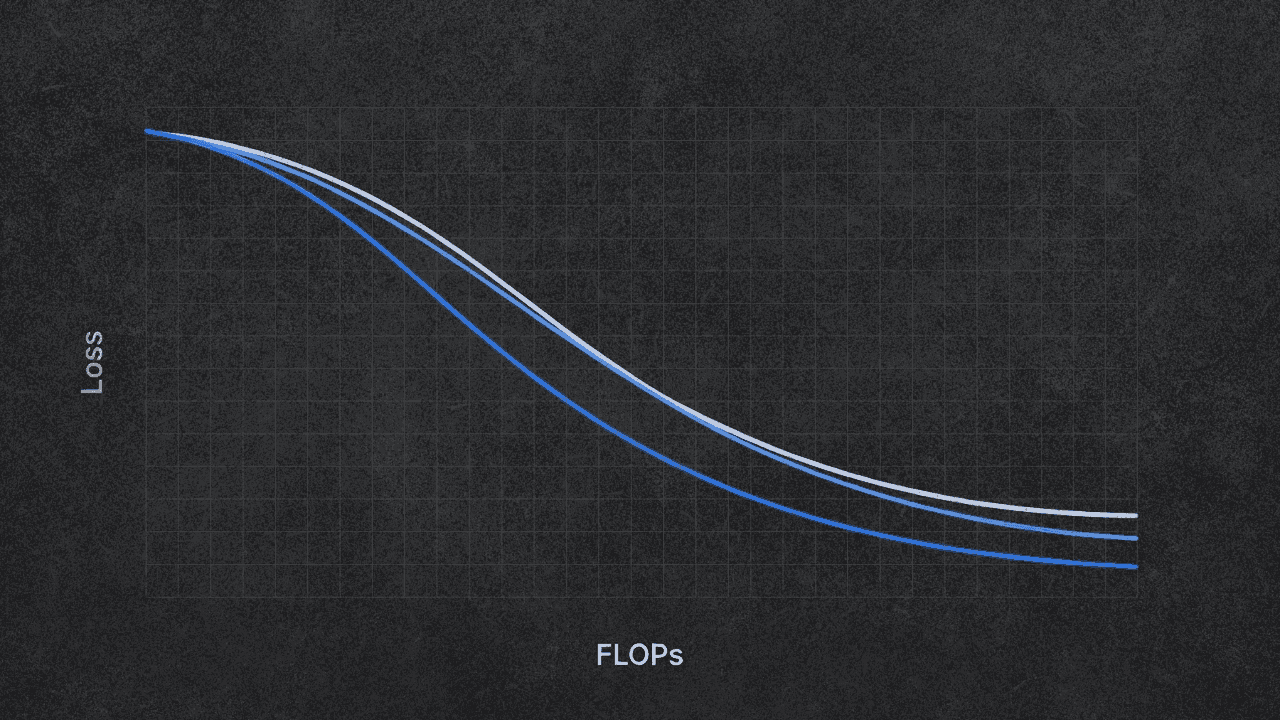
Карпати показывает вот что: если правильно применять законы масштабирования, не нужно гадать, поможет ли дополнительный compute. Вы просто знаете. Кривые не пересекаются. У каждого размера модели есть одна правильная длина обучения, и её можно вычислить заранее.
Он обучил 11 моделей (d10–d20) примерно за 4 часа на 8×H100. Общая стоимость: около $100. Кривые валидационного лосса выглядят именно так, как должны — чистые, параллельные, без пересечений. Если ваши кривые пересекаются, с вашим сетапом что-то не так.
Chinchilla, но с другим коэффициентом
Про законы масштабирования. Nanochat воспроизводит находку Chinchilla: параметры и токены масштабируются одинаково с ростом compute, оба растут как C^0.5. Это значит, что оптимальное соотношение данных к параметрам постоянно независимо от того, сколько compute вы используете.
Интересное начинается дальше. Chinchilla измерил это соотношение как 20. Nanochat получает 8.
Разница существенная. Карпати предлагает два объяснения: возможно, оптимизатор Muon предпочитает большие модели с коротким обучением, или это артефакт меньшего масштаба экспериментов. К какому-то одному объяснению он не склоняется. Мне нравится, что он просто говорит «не знаю» вместо того, чтобы выдумывать.
Метрика CORE
Сравнивать валидационный лосс — занятие неблагодарное. Разные распределения данных, разные токенизаторы, разное всё. Карпати хотел сравниться с GPT-2 и GPT-3, поэтому взял метрику CORE из статьи DCLM. 22 бенчмарка, агрегированных в одно число.
С GPT-2 всё просто — модели публичные. С GPT-3 пришлось изворачиваться. Модели так и не выложили, но в статье есть таблицы с оценками. Карпати нашёл 6 задач, которые пересекаются между CORE и тем, что указано в статье GPT-3, использовал GPT-2 для калибровки и оценил остальное. Методология в jupyter-ноутбуке, если хотите проверить.
Сколько стоит догнать GPT-2
Таблица экстраполяции в конце — это то, что все будут скриншотить. Догнать GPT-2 Small (124M параметров, CORE 0.114): около $3, 8 минут. GPT-2 XL (1.6B параметров, CORE 0.257): $546, 22 часа.
Тут много экстраполяции. Карпати сам это признаёт. Но как проверка на адекватность: предсказанные FLOPs для достижения производительности GPT-3 175B составляют 5.7e23. Реальный тренировочный запуск GPT-3 был около 3e23. Порядок сходится.
Подкол в сторону modded-nanogpt
В обсуждении есть короткий выпад в адрес modded-nanogpt. Карпати говорит, что некоторые изменения «слегка подыгрывали метрике» за счёт batch size 1 с очень длинными последовательностями. Проблема в том, что меньше токенов оказываются с обрезанным контекстом в начале батчей, что искусственно улучшает валидационный лосс. Улучшение ненастоящее.
Формулировка вежливая. «Немного тонко» тут делает много работы.
Скучные детали, кратко
Гиперпараметры подбирались. Learning rate близок к оптимальному. Warmdown ratio сдвинулся с 0.2 до 0.4. Длина последовательности 2048 балансирует контекст и разнообразие документов. Batch size 0.5M токенов чуть великоват для чистой FLOPs-эффективности, но хорош для wall-clock time. «Далеко не исчерпывающе».
Что дальше
У miniseries v2 простая цель: поднять линию выше. Тот же фреймворк, больше отдачи на доллар. Целевая область: код предобучения.
Главная ценность тут не в какой-то конкретной модели. А в том, что кто-то наконец собрал чистую, воспроизводимую демонстрацию того, что законы масштабирования реально работают на доступных масштабах. Можете проверить сами за сотню долларов. Код выложен. Методология задокументирована.
Должен ли коэффициент Chinchilla быть 8 вместо 20 — это потребует больше экспериментов на большем масштабе.