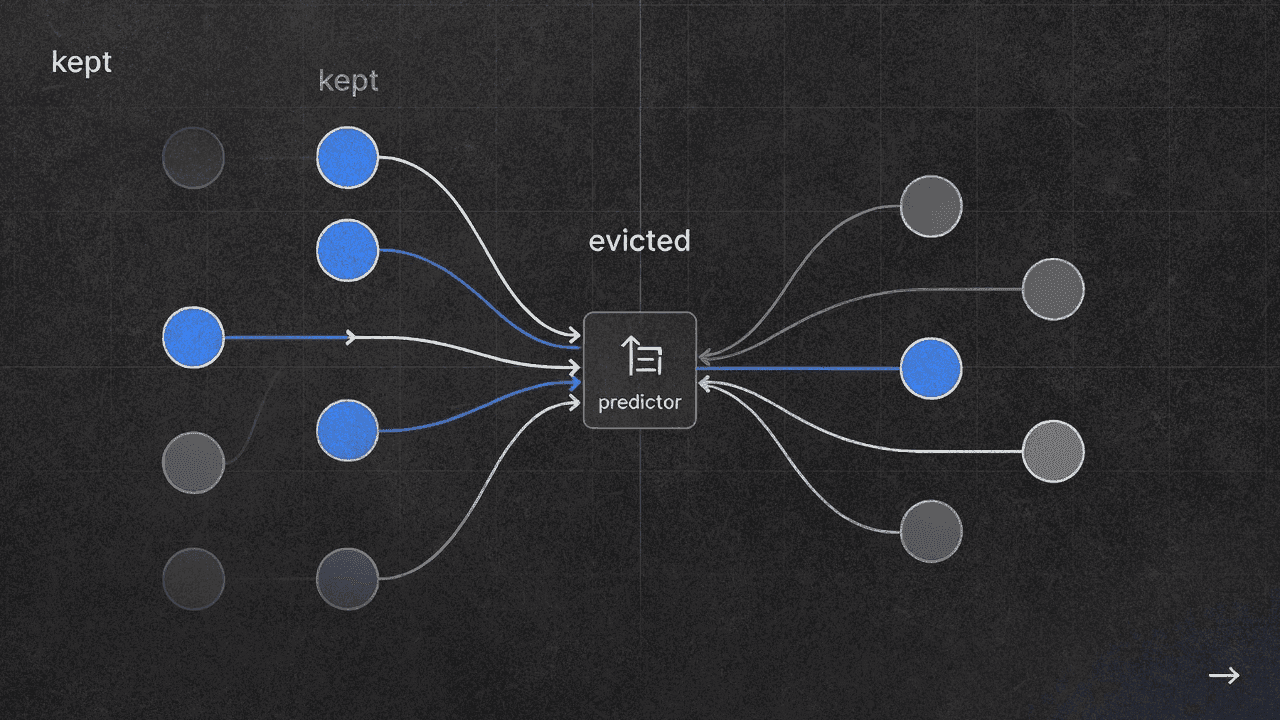
Исследователи Nvidia опубликовали статью с описанием KVzap. Метод позволяет сжимать KV-кеш в трансформерах в 2-4 раза. Суть в том, что маленькая суррогатная модель учится предсказывать, какие пары ключ-значение можно безопасно выкинуть. Накладные расходы для линейного варианта составляют 0,02%.
Проблема, которую никто толком не решил
KV-кеш остаётся главным узким местом по памяти. Каждый обработанный токен сохраняется как пара ключ-значение для каждого слоя и каждой головы внимания. Для модели на 65 млрд параметров при контексте 128k это примерно 335 ГБ памяти. Не веса, заметьте. Только кеш.
Большинство методов сжатия бьют не туда. Grouped Query Attention, который используется в Llama 3 и Qwen, сжимает по оси голов. Multi-head Latent Attention от DeepSeek работает с размерностью ключей и значений. Оба подхода помогают, но основная избыточность лежит в оси токенов. Не все 128 000 токенов одинаково важны для следующего предсказания.
У KVzip была правильная идея
Оригинальный KVzip из Сеульского национального университета это понял. Их находка: попросить модель «повторить предыдущий контекст», используя только сжатый кеш. Если реконструкция работает, значит сжатие было без потерь. Токены, которые почти не влияют на реконструкцию, можно выбросить.
Работало неплохо. Сжатие в 3-4 раза с минимальной потерей качества на задачах QA, поиска, рассуждений. Но есть подвох, зарытый в деталях: по сути, prefill выполняется дважды. Этап сжатия использует ту же модель для оценки важности, то есть вычисления на дорогой стадии prefill удваиваются. Для единичных запросов это ещё терпимо. Для продакшн-нагрузок, где промпты обрабатываются постоянно, это больно.
Что сделала Nvidia
KVzap обходит дорогой этап реконструкции. Вместо прогона полной модели для оценки важности токенов они обучают крошечный предиктор, который смотрит на скрытое состояние каждого токена и выдаёт оценку важности.
Насколько крошечный? Либо один линейный слой, либо двухслойный MLP, обученный отдельно для каждого слоя трансформера. Линейный вариант добавляет 0,02% FLOP. MLP-версия около 1,1%. Оба числа теряются на фоне квадратичной стоимости внимания на длинных контекстах.
Обучающие данные берутся из датасета препрейнинга Nemotron с английским текстом, кодом и мультиязычными материалами. Метки генерируются офлайн полной процедурой скоринга KVzip, а потом эти оценки дистиллируются в лёгкий предиктор.
Второе изменение: пороговое отсечение вместо фиксированных бюджетов. KVzip говорит «оставь ровно 50% токенов». KVzap говорит «оставь всё выше порога важности τ». Сжатие становится адаптивным. Плотные, информационно насыщенные промпты сохраняют больше токенов. Избыточные сжимаются сильнее. Звучит логично, хотя хотелось бы увидеть, как часто адаптивная степень сжатия промахивается мимо цели на практике.
Работает ли это
На лидерборде KVpress KVzap догоняет или обходит 15 других методов на Qwen3-8B и Llama-3.1-8B-Instruct. Бенчмарк RULER на 4k токенов показывает, что метод идёт практически вровень с кривой производительности KVzip, пока остальные отстают.
Тестировали до Qwen3-32B на RULER (синтетические задачи с длинным контекстом) и LongBench (реальные документы). Плюс AIME25, это 30 задач математических олимпиад. Результаты держатся на всех.
Но вот чего я не нашёл: поведения при масштабировании за пределами 32B. В статье тесты до 32 млрд параметров и 128k токенов. Продакшн-модели вроде DeepSeek-V3 весят 671 млрд параметров. Работает ли суррогатный подход, когда базовая модель в 20 раз больше? Статья молчит.
Проблема порога
Выбор τ нетривиален. Слишком высокий порог выкидывает важные токены. Слишком низкий почти ничего не сжимает. В статье показаны разные пороги с разными коэффициентами сжатия, но чёткого руководства, как выставить τ для новой модели или задачи, нет.
Код выложен и интегрируется с их библиотекой kvpress. Можно указать threshold=-4 и получить... какой-то коэффициент сжатия в зависимости от входных данных. Для исследований это, наверное, нормально, но для продакшна явно нужен дополнительный инструментарий.
Что здесь важно
Интересен не сам коэффициент сжатия. Другие методы дают похожие цифры. Интересны накладные расходы. При 0,02% дополнительных FLOP это можно включить не задумываясь. Решение становится «есть ли у меня проблемы с памятью?» вместо «стоит ли выигрыш от сжатия вычислительных затрат?».
Для инференс-серверов с длинноконтекстными нагрузками это меняет расклад. Больше не нужно жертвовать латентностью ради памяти. Просто получаешь память обратно.
Обобщается ли суррогатное обучение на модели вне их тестового набора, вопрос открытый. И вызывает ли пороговый подход проблемы на граничных случаях, тоже неясно. Но как отправная точка для практического сжатия KV-кеша это выглядит более готовым к деплою, чем всё, что я видел раньше.
Код под лицензией MIT, если захотите попробовать.
IMAGE PROMPT
Technical illustration showing a neural network layer with key-value pairs flowing through, some highlighted in blue (kept) and others fading to gray (evicted). Clean, minimal style with dark background. Emphasis on the small predictor module intercepting the hidden states. No text. 16:9.
featuredImageAlt: Схема сжатия KV-кеша с оценкой важности токенов
EDITOR NOTES
- Claims to verify: 335 GB KV cache figure for 65B model at 128k tokens, 0.02% FLOP overhead claim
- Dates to check: January 12, 2026 paper submission date confirmed via arXiv
- Update by: Check for production deployment announcements, any integration with vLLM or TensorRT-LLM
Sources
| Anchor Text | URL | Location |
|---|---|---|
| опубликовали статью | https://arxiv.org/abs/2601.07891 | Lead paragraph |
| Оригинальный KVzip | https://arxiv.org/abs/2505.23416 | KVzip section |
| лидерборде KVpress | https://github.com/NVIDIA/kvpress | Results section |
| Код выложен | https://github.com/NVIDIA/kvpress/tree/main/kvzap | Threshold section |



